Using GraphQL or REST, that is the question

This blog has been dormant for too long – it’s time to post another article. In order to live up to the blog title, this article will combine some old and seasoned stuff (PostgreSQL and Shakespeare’s works) with the latest trends for agile developers (GraphQL, asyncio and type hints for Python).
GraphQL is a new query language for building APIs that looked quite intriguing to me when I first came across it, as it promised to solve several drawbacks of the typical REST APIs I was using so far. After tinkering with it for a while, I became hooked, and as a Pythonista, I wanted to use GraphQL for my Python backends, too. This was not a real problem: GraphQL has been ported to many programming languages already, and Python is one of them. The most well-known GraphQL library for Python is called Graphene. Graphene is built upon GraphQL-core, which is a Python port of GraphQL.js, the reference implementation for GraphQL written in JavaScript.
One thing that bothered me a bit though was that GraphQL.js advanced in a faster pace than GraphQL-core. It is currently at version 0.14 (now renamed to version 14) while GraphQL-core decoupled from the development of GraphQL.js at version 0.6. I wondered if I could re-implement GraphQL-core based on the latest GraphQL.js code, while also using the latest features available in Python 3.6, like asyncio, f-strings and type hints, which could not be used by GraphQL-core since it tried to be backward compatible with Python 2. Since that seemed to be a good opportunity to learn GraphQL and all of these new Python features at the same time, I tinkered with this in my spare time in the last months. Re-implementing GraphQL-core took way longer than I thought, since GraphQL.js is actually quite extensive, and I wanted to port everything faithfully, including the complete test suite. Kudos to Syrus Akbary who already created not only GraphQL-core, but also Graphene and other GraphQL libraries before I even started my tinkering with GraphQL. Recently he suggested to join forces and publish my new implementation of the library for Python 3.6+ as GraphQL-core-next under the GraphQL-Python umbrella.
In this article I want to exemplify how GraphQL-core-next can be used to create a GraphQL API for a PostgreSQL database that stores Shakespeare’s works, running on an asynchronous Python backend server. Sounds exciting? Then grab your keyboard and code along with me!
The database
For our example, I chose PostgreSQL as the database engine for the backend. Of course you can also use any other SQL or NoSQL database to build a GraphQL server. Actually, you don’t even need a database. For instance you could fetch the data from another web service, maybe a legacy system that you want to make accessible via GraphQL. However, I really like the PostgreSQL database for my Python backends, as it is very reliable, fast and flexible.
If you want to follow along, make sure you have PostgreSQL installed and running on your local machine. It is available on most Linux distributions and macOS, and you can also download and easily install binary packages for Windows, Linux and macOS.
For the database content, I chose the data from Open Source Shakespeare, which has been put into a PostgreSQL database schema by Catherine Devlin. After downloading the shakespeare.sql file, you can create a new database shakespeare and import the database schema along with all of the data like this:
createdb shakespeare
psql shakespeare < shakespeare.sql
You can also use pgAdmin to create the database, import the data, and examine the database. You should be able to run SQL queries like this one using pgAdmin or psql:
select substring(plaintext, 1, 42) from paragraph
where workid='hamlet' and charid='hamlet'
and plaintext like '%is the question%'
The database contains six tables, but for simplicity sake, we will restrict ourselves to only the two tables work and character and their association table character_work. Our goal for this small tutorial is to create a GraphQL API for requesting the data in these tables. This API will then allow us to execute GraphQL queries like this one:
{
works {
id
title
year
genre
characters {
id
name
description
}
}
}
This GraphQL query is pretty self explanatory. It asks for all the works of shakespeare, with their title, year and genre, and all the characters appearing in these works, with their name and description. In a REST API, to get all this information, you would first have to request a list with the work IDs, then send separate requests for getting the details and list of character IDs for each work, and then send another heap of requests for getting the names of all these characters. You would have to send each of these REST requests to a different endpoint. In GraphQL, you’re using the same endpoint for all of your queries.
If you want to get the details for a single character with a given ID, similar to a GET request in a REST API, you could use the following GraphQL query:
{
character(id:"hamlet") {
name
description
}
}
As the result of this query, the GraphQL API would then return the following JSON document:
{
"data": {
"character": {
"name": "Hamlet",
"description": "son of the former king and nephew to the present king"
}
}
}
Contrary to a GET request in a REST API, we only get the fields in the result that we have explicitly requested, and in the same structure that has been specified in the request. This is one of the many really nice features of GraphQL.
Using mutations instead of queries, it is also possible to add or edit data in the database via a GraphQL API, just as you can do with POST or PUT requests via a REST API. With GraphQL you can also push data from the server to the client using subscriptions. Again, we will not cover these aspects of GraphQL APIs in this article to keep things simple. We will also not talk about authentication, authorization or other security aspects in this article, but of course there are ways to deal with that in a GraphQL API as well, and you’re well advised to think about these aspects very carefully when implementing GraphQL APIs for serious applications.
The resolvers
In a GraphQL server, the so-called “resolver” functions are doing all the work of fetching the actual data. Each resolver function is responsible for one data field, which can have an object type that needs to be further resolved, like the work object, or have a leaf type that resolves to a scalar value like the name of a character.
The resolver functions can be synchronous or asynchronous. Since we want to build an asynchronous HTTP server, we need to use asynchronous resolver functions which are implemented with async def instead of the usual def keyword in newer Python versions. The resolver functions eventually must fetch the data from the database using an asynchronous PostgreSQL interface. I chose asyncpg for this example, but you can also use aiopg with only minor changes to the code.
Let’s put all the resolvers into one Python module resolvers.py. If you want to follow along, create this file now and put the following code into it. Don’t worry, I will explain in more detail what’s going on in this module below. Make sure you have Python 3.6 or newer installed, because we are making use of some recent features and because this is also required by GraphQL-core-next.
# resolvers.py
# Helper functions to fetch rows from the database
async def fetch_row(info, query, *args):
"""Fetch a single row from the database"""
query += " order by 1"
async with info.context['db'].acquire() as con:
row = await con.fetchrow(query, *args)
if not row:
raise ValueError('Not found')
return dict(row) if row else None
async def fetch_rows(info, query, *args):
"""Fetch a list of rows from the database"""
query += " order by 1"
async with info.context['db'].acquire() as con:
rows = await con.fetch(query, *args)
return [dict(row) for row in rows]
# SQL query to fetch rows from the work table
select_work = """
select workid as id, title, year, genretype as genre, notes,
totalwords as "totalWords", totalparagraphs as "totalParagraphs"
from work"""
# SQL query to fetch rows from the character table
select_character = """
select charid as id, charname as name, description,
speechcount as "speechCount"
from character"""
# The actual resolvers
async def resolve_work(root, info, id):
return await fetch_row(info, f"{select_work} where workid=$1", id)
async def resolve_works(root, info):
return await fetch_rows(info, select_work)
async def resolve_character(root, info, id):
return await fetch_row(info, f"{select_character} where charid=$1", id)
async def resolve_characters(root, info):
return await fetch_rows(info, select_character)
async def resolve_works_for_char(char, info):
query = f"{select_work} natural join character_work where charid=$1"
return await fetch_rows(info, query, char['id'])
async def resolve_chars_for_work(work, info):
query = f"{select_character} natural join character_work where workid=$1"
return await fetch_rows(info, query, work['id'])
In the code above we first define two helper functions fetch_row() and fetch_rows() for fetching a single row and a couple of rows from the database. As the first parameter, they take an info object, which is something that is used by GraphQL to pass information about the execution state of the GraphQL query to the resolvers. The info object also has a context attribute with per-request state. This is normally used to pass authentication information or database sessions. We use it to pass a dictionary with a db key that has a pool of asynpg database connections as value. Using the acquire() context handler, we get a database connection from that pool, and then run fetchrow() or fetch() on that connection to fetch a single row or multiple rows from the database, passing the actual SQL query and any parameters for that query. Since this is an asynchronous operation, its result must be awaited.
Note that before returning the results, we convert them to ordinary Python dicts. The reason for this is that we want to make use of the default resolvers that GraphQL-core-next provides. These default resolvers normally use attribute access to fetch values from objects if they don’t look like Python dicts. The existence of these default resolvers relieves us from the burden of having to write resolvers for each and every column in our database.
Next we define the SQL queries to be used for fetching rows from the work and character tables. Note that we aliased some lowercase columns as camelCase because that is the style convention for naming fields in an GraphQL API.
Finally, we define the actual resolvers. Again, we are using async def instead of def because we want to run everything asynchronously.
Note that there are two types of resolvers. The first four resolvers are used for the top level of the query, while the last two are used for nested queries. Those nested resolvers take the previous object as their first argument, while the root resolvers get a special root object instead, which is not necessary and therefore ignored in our case. As the second argument, the resolvers take the mentioned info object. The additional arguments are those passed to the GraphQL query. For instance, the resolvers for fetching an individual work or character take the id argument (another GraphQL convention) which corresponds to the workid and charid primary key columns in the database accordingly. You could also pass other arguments to the resolvers that fetch lists of works or characters, like a search string for the title or name or the fields to be used for sorting the list etc. But again, we want to keep things simple here.
The schema
To build a GraphQL API, we not only need the resolver functions, but we also need to create a GraphQL schema that exactly defines which data fields of which types can be queried in which places.
GraphQL-core-next provides the building blocks to create such a schema in Python code. Here is how you would use them to build the schema for our example API that gives access to Shakespeare’s works:
# schema.py
from enum import Enum
from graphql import (
GraphQLArgument, GraphQLEnumType, GraphQLField,
GraphQLID, GraphQLInt, GraphQLList, GraphQLNonNull,
GraphQLObjectType, GraphQLSchema, GraphQLString)
import resolvers
# Define the Schema using GraphQL types:
class GenreType(Enum):
COMEDY = 'c'
HISTORY = 'h'
POEM = 'p'
SONNET = 's'
TRAGEDY = 't'
F = GraphQLField
L = GraphQLList
NN = GraphQLNonNull
WorkType = GraphQLObjectType('Work', lambda: {
'id': F(NN(GraphQLID)),
'title': F(NN(GraphQLString)),
'year': F(NN(GraphQLInt)),
'genre': F(NN(GraphQLEnumType('GenreType', GenreType))),
'notes': F(GraphQLString),
'totalWords': F(NN(GraphQLInt)),
'totalParagraphs': F(NN(GraphQLInt)),
'characters': F(NN(L(NN(CharacterType))),
resolve=resolvers.resolve_chars_for_work)})
CharacterType = GraphQLObjectType('Character', lambda: {
'id': F(NN(GraphQLID)),
'name': F(NN(GraphQLString)),
'description': F(GraphQLString),
'speechCount': F(NN(GraphQLInt)),
'works': F(NN(L(NN(WorkType))),
resolve=resolvers.resolve_works_for_char)})
query_type = GraphQLObjectType('Query', {
'work': F(NN(WorkType),
args={'id': GraphQLArgument(NN(GraphQLID))},
resolve=resolvers.resolve_work),
'works': F(NN(L(NN(WorkType))),
resolve=resolvers.resolve_works),
'character': F(NN(CharacterType),
args={'id': GraphQLArgument(NN(GraphQLID))},
resolve=resolvers.resolve_character),
'characters': F(NN(L(NN(CharacterType))),
resolve=resolvers.resolve_characters)})
schema = GraphQLSchema(query_type)
Just put the code above in a file named schema.py and save it along with the resolvers.py file you already created.
At the top of the file, we’re importing all the building blocks I mentioned above. These are used to build the two types we are using in our example, the WorkType corresponding to the work table and the CharacterType corresponding to the character table in the database. Then we also define the root type Query with the four fields that can be requested on the top level of a GraphQL query: work, works, character, and characters. We use the plural form for fields that refer to a list of objects, so that you can intuitively understand what you can expect when requesting the respective field.
As you see, every type gets passed a name and a dictionary of GraphQL fields. The keys are the field names and the values are the field types. The fields are resolved either by the default resolvers or the specified resolver functions. For instance, the WorkType has a field characters which is a List of CharacterType objects. We use the GraphQLList wrapper to specify that. We also use the GraphQLNonNull wrapper to specify that both the list itself and all of its elements may not be null. For this field, we are using the resolve_chars_for_work() resolver function. The four root resolvers are used for the four fields that can be queried on the root level. Two of them use an GraphQLArgument in order to pass the id which itself is of type GraphQLID. This type is not much different from GraphQLString, but indicates that the value should be interpreted as a unique ID.
The WorkType also has a genre field that is an GraphQLEnumType, i.e. an enumeration of possible values, like COMEDY or POEM. The code shows how it is possible to map these enum values used by the GraphQL API to the actual values in the backend database, which uses single lowercase characters to encode the genre. The code shows how you can uses a Python Enum for this purpose, but you can also use a dictionary.
The Python code above is pretty straightforward, albeit a bit ugly and verbose. I tried to reduce the verbosity a bit by using alias names for the most frequently used GraphQL types. As an alternative to building the GraphQL schema in Python code using GraphQL types as building blocks, it is also possible with GraphQL-core-next to define the schema using the GraphQL schema definition language (SDL). The only drawback here is that the SDL does not describe the server-side implementation of the schema, so you will need to reconnect the resolvers and mapping of enum values manually after creating the schema from the SDL if you want to build a fully working GraphQL server. Here is the code if you want to follow this alternative approach:
# schema.py
from graphql import build_schema
import resolvers
# Build the schema using SDL:
schema = build_schema("""
type Query {
work(id: ID!): Work!
works: [Work!]!
character(id: ID!): Character!
characters: [Character!]!
}
enum Genre {
COMEDY
HISTORY
POEM
SONNET
TRAGEDY
}
type Work {
id: ID!
title: String!
year: Int!
genre: Genre
notes: String
totalWords: Int!
totalParagraphs: Int!
characters: [Character!]!
}
type Character {
id: ID!
name: String!
description: String
speechCount: Int!
works: [Work!]!
}
""")
# Add the server-side know-how:
fields = schema.query_type.fields
fields['work'].resolve = resolvers.resolve_work
fields['works'].resolve = resolvers.resolve_works
fields['character'].resolve = resolvers.resolve_character
fields['characters'].resolve = resolvers.resolve_characters
for name, value in schema.get_type('Genre').values.items():
value.value = name[0].lower()
fields = schema.get_type('Work').fields
fields['characters'].resolve = resolvers.resolve_chars_for_work
fields = schema.get_type('Character').fields
fields['works'].resolve = resolvers.resolve_works_for_char
Event though these two files look very different, they achieve the same goal of defining a GraphQL schema that can be used for our GraphQL server, which we will build next.
The server
Now that we have a GraphQL schema, it’s time to build the actual GraphQL server. We want it to be an asynchronous HTTP server, so we are building it with aiohttp. We also need asyncpg and of course GraphQL-core-next. These all can be installed very easily with pip or pipenv:
pip install aiohttp asyncpg GraphQL-core-next
Creating the GraphQL server with aiohttp is not too complicated. You can copy the following code and save it as server.py along with the resolvers.py and schema.py files you already created. Again, I’ll explain how it works below.
# server.py
from aiohttp import web
import asyncpg
from graphql import graphql
from schema import schema
async def init_db(app):
app['db'] = await asyncpg.create_pool(database='shakespeare')
async def close_db(app):
await app['db'].close()
async def get_query(request):
content_type = request.content_type
if content_type == 'application/graphql':
return await request.text()
elif content_type == 'application/json':
return (await request.json())['query']
async def graphql_view(request):
query = await get_query(request)
result = await graphql(
schema, query, context_value={'db': request.app['db']})
errors = result.errors
if errors:
errors = [error.formatted for error in errors]
result = {'errors': errors}
else:
result = {'data': result.data}
return web.json_response(result)
app = web.Application()
app.on_startup.append(init_db)
app.on_shutdown.append(close_db)
app.router.add_post('/graphql', graphql_view)
web.run_app(app, host='127.0.0.1', port=8080)
Before running this code, a few explanations. At the top of the file, we’re importing all of our dependencies. The graphql package is provided by GraphQL-core-next. The schema module is the one we just created above (using either of the two approaches).
Next we define a few asynchronous functions (coroutines) to be used by aiohttp. The init_db() function creates a pool of database connections to the shakespeare database and stores it in the global app object which is an Application instance created with aiohttp. The function is executed when the web server starts. The close_db() function closes the database connection pool properly when the web server shuts down. get_query() is a helper function that gets the actual GraphQL query from a web request. And finally, the graphql_view() function is the actual request handler for our GraphQL requests. It is called whenever a URL starting with /graphql is requested from our server as a POST request. We only care about that /graphql route here and ignore all other URLs.
In our graphql_view() request handler, the following things happen: First, we get the actual GraphQL query string with the get_query() function. Since this is an asynchronous function, we must await the result. Next, we call the asynchronous grapqhl() function provided by the graphql package and again await its result. This function gets passed our GraphQL schema, the GraphQL query string, and a context object that will be passed to the resolvers. This is a dictionary, inside which we pass the reference to our global database connection pool under the db key.
The graphql() function is the one that actually executes the query in the request against the schema that we provided, using the resolver functions that we attached to the schema. Its result is an ExecutionResult object which has a data attribute and an errors attribute. The former contains the actual result of the query if it was valid and could be executed without errors. Otherwise, errors attribute will contain a list of GraphQLErrors with the positions of the validation or execution errors and corresponding error messages.
The code at the bottom of the file sets up an aiohttp application, makes sure the init_db() function runs on startup and close_db on shutdown, mounts the graphql_view() request handler to the /graphql route, and finally starts the web server on localhost port 8080.
The Client
For testing the GraphQL API, you can use a GraphQL client like Insomnia (which was actually a REST client, but now speaks GraphQL, too). Run the server.py file and then start Insomnia. Create a new workspace “Shakespeare”. There, create a new request “Hamlet”, selecting “POST” as the request method and “GraphQL query” as the body. Change the URL of the query to http://localhost:8080/graphql and enter our GraphQL query from above as the body. You should get the expected output:
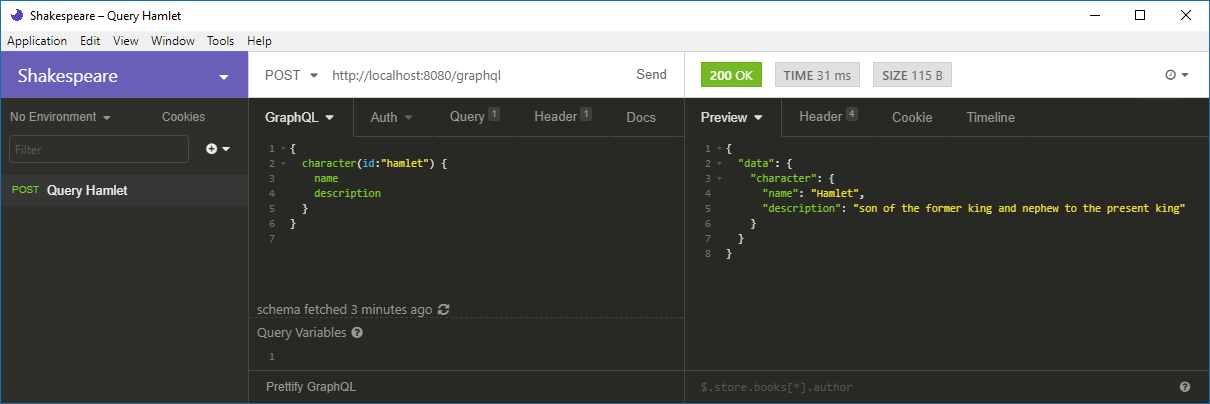
Another way way of testing the GraphQL API is by using the GraphiQL IDE which can be integrated into the server or started as a standalone app using Electron.
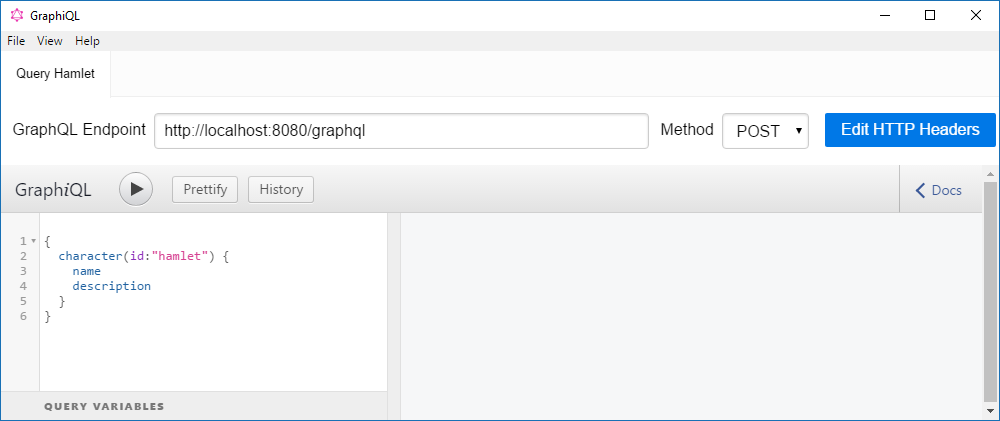
When you click on the “Docs” Button on the right side of the GraphiQL window, you can browse through the documentation of all the types defined in our schema. You would also see descriptions for the types and enum values if we had added these when defining the schema. This is what I really like about GraphiQL. Like Insomnia, GraphiQL also uses the schema information to auto suggest field and argument names, and translates GraphQLErrors into squiggly red lines under the corresponding positions in the query. Once you got accustomed to this kind of convenience when testing queries against your API, you don’t want to miss it any more.
Let’s try to use the API we created to find out the title of Shakespeare’s work in which the character Hamlet appeared. Ok, this is not a very difficult question, you say. So let’s try to also find out in the same query, in which year that work has been written and how many words it contains. This is still quite easy to do with GraphiQL and our Shakespeare GraphQL API server:
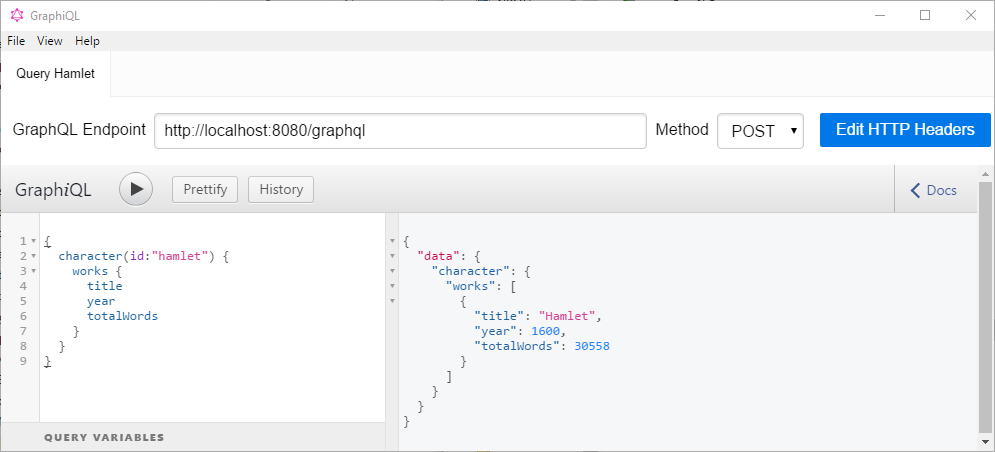
Have fun playing around with our small API. Maybe you want to extend it to the other data that’s available in the database, making it possible to retrieve the full text of Shakespeare’s works, or build a small single page web app using this API.